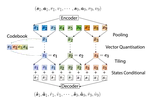Planning-based reinforcement learning has shown strong performance in tasks in discrete and low-dimensional continuous action spaces. However, scaling such methods to high-dimensional action spaces remains challenging. We propose Trajectory Autoencoding Planner (TAP), which learns a compact discrete latent action space from offline data for efficient planning, enabling continuous control in high-dimensional control with a learned model.